Longest palindromic substring
Not to be confused with Longest palindromic subsequence.
The longest palindromic substring problem is exactly as it sounds: the problem of finding a maximal-length substring of a given string that is also a palindrome. For example, the longest palindromic substring of bananas is anana. The longest palindromic substring is not guaranteed to be unique; for example, in the string abracadabra, there is no palindromic substring with length greater than three, but there are two palindromic substrings with length three, namely, aca and ada. In some applications it may be necessary to return all maximal-length palindromic substrings, in some, only one, and in some, only the maximum length itself. This article discusses algorithms for solving these problems.
Contents
Toward a better bound[edit]
Thus, the best possible worst-case running time lies between 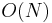 and
and 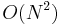 . We now show that the problem can be solved in
. We now show that the problem can be solved in 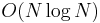 time using standard data structures from the literature, the suffix tree and the suffix array.
time using standard data structures from the literature, the suffix tree and the suffix array.
Suffix array[edit]
The suffix array is a sorted list of the suffixes of a given string, indexed by first character. For example, the suffix array of bananas is [1, 3, 5, 0, 2, 4, 6], corresponding to the suffixes [ananas, anas, as, bananas, nanas, nas, s]. Simple linear-time algorithms now exist for computation of suffix arrays of strings with constant or integer alphabets.[1]
Once the suffix array of a string has been computed, a simple linear-time algorithm[2] will compute the length of the longest common prefix of each pair of adjacent suffixes in the suffix array. The array containing these lengths is known as the lcp array.
If we want to know the longest common prefix of any pair of suffixes, not necessarily lexicographically adjacent, we locate those two suffixes in the suffix array and then find the minimum entry in the lcp array in the range they delimit, hence reducing the problem to a range minimum query. For example, the string teetertotter has suffix array [1,10,4,2,7,11,5,0,9,3,6,8] and lcp array [1,2,1,0,0,1,0,2,3,1,1], because the suffixes starting at positions 1 and 10 have one character in common at the beginning, the suffixes starting at positions 10 and 4 have two characters in common at the beginning, and so on. Suppowe we want to determine the length of the longest common prefix of the suffixes ter (9) and tter (8), which are not adjacent in the suffix array (it is irrelevant that they are adjacent in the string itself). We locate 6 and 8 in the suffix array, and we see from the lcp array that the longest common prefixes of the pairs of suffixes starting at locations 9 and 3, 3 and 6, and 6 and 8 have lengths 3, 1, and 1, respectively. This is a contiguous range of the lcp array. The minimum value in this array, 1, is the answer.
To solve the problem at hand, we will concatenate our string with a unique separator and a reversed copy of itself, so that rearrangement becomes, for example, rearrangement#tnemegnarraer, and then build the suffix array and longest common prefix array for the new string. Then we iterate through all positions in the original string and find the longest palindromic substring centered at each one. To do so, we mirror the current position across the centre of the string, and then take longest common prefixes.
Even case[edit]
To determine the longest palindromic substring centered between the two r's (which must be of even length), we consider the suffixes starting at the underlined locations: rearrangement#tnemegnarraer. We see that the longest common prefix of these two suffixes has length 2 (underlined: rearrangement#tnemegnarraer). But because the second half is a reversed copy of the first half, we know the ra in the second half is actually the ar in the first half just before our current position: rearrangement#tnemegnarraer. Thus we have determined that the longest palindromic substring here has length 4. In general we find the character just after our current position in the original string, and the character just before it in the reversed string, and find the longest common prefix using the lcp array and RMQ.
Odd case[edit]
In the odd case, we are centered at some character of the original string. In this case, we examine the suffix starting at the character in the original string immediately following it, and the suffix in the reversed string starting at the character immediately preceding it. If we were centered at the m in rearrangement, then, we would be examining the suffixes starting at the underlined characters: rearrangement#tnemegnarraer. We see that the longest common prefix has length 1, and we reflect the e in the reversed half back onto its position in the first half, hence, rearrangement#tnemegnarraer is the longest palindromic substring centered at the m.
Complexity[edit]
Since positions for the centre are considered, and a range minimum query can be executed in 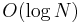 time (or constant time with preprocessing), the time complexity of this solution is .
time (or constant time with preprocessing), the time complexity of this solution is .
Suffix tree[edit]
The suffix tree is a compressed trie of the suffixes of the string. A detailed discussion of the structure of the suffix tree is given in the article. There exist linear-time algorithms[3] for construction of suffix trees, as well. There are two possible approaches here: we can either concatenate the string with a unique separator and a reversed copy of itself, as with the suffix array, or we can build a generalized suffix tree of the string and its reverse. We proceed as we did with the even and odd cases in the suffix array section, finding longest common prefixes starting at almost-corresponding positions in the original and reverse strings. It is not too hard to see that this is a lowest common ancestor query on the tree. For example, to find the longest palindromic substring of even length centered between the two r's in rearrangement, we could build the suffix tree for rearrangement#tnemegnarraer, locate the leaves corresponding to the suffixes starting at the underlined characters, and find their lowest common ancestor. The depth of this node is the length of the longest common prefix of these two suffixes. Here it is 2, so we know that the substrings underlined match: rearrangement#tnemegnarraer, giving the palindromic substring rearrangement#tnemegnarraer. LCA queries can be executed in constant time after preprocessing time, giving an solution.
Existence of a linear-time algorithm[edit]
It is possible to execute LCA queries on a tree with nodes in time using a technique due to Gabow and Tarjan.[4] This shows that a linear-time solution exists, which puts to rest the question of the best possible efficiency for a solution to the longest palindromic substring problem.
A simple asymptotically optimal solution[edit]
Although we have already established that the solution using suffix trees and LCA queries is asymptotically optimal, we are driven to seek a better solution for many reasons. The suffix tree based solution:
- requires much code to implement
- has a high constant factor on runtime
- consumes a great deal of memory, and
- is still with general alphabets.
However, there exists a simpler, shorter, faster, less memory-hungry algorithm[5] which accesses the string only by comparing its characters for equality (and hence has running time independent of alphabet size). This is known as Manacher's algorithm.[6][7] Again we will compute the longest palindromic substring centered around each possible position (so that returning all longest palindromic substrings is as easy as simply finding the maximum possible length for a palindromic substring). Our algorithm will return a longest palindrome array: an array in which the 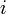 th element contains the length of the longest palindrome centered around the th position from the left. (Note that the parities of elements in the longest palindrome array alternate.)
th element contains the length of the longest palindrome centered around the th position from the left. (Note that the parities of elements in the longest palindrome array alternate.)
The algorithm processes the string from left to right, and fills in the longest palindrome array in the same order, so that when any given position is being considered, the longest palindromes centered around all positions to the left are already known. The algorithm distinguishes two kinds of positions: "interesting" positions and "uninteresting" positions. The algorithm "hops" from each interesting position to the one immediately to the right. It spends amortized constant time on each interesting position. Interesting positions are so named because any maximal-length palindromic substring overall must be centered at one of them. Uninteresting positions' entries in the longest palindrome array can be computed in constant time "in passing" from one interesting position to the next.
We will proceed through a series of observations to derive the algorithm. First, the designation of interesting and uninteresting positions is not unique; in particular, any uninteresting position can be relabelled interesting without affecting correctness or consistency. That being said, we begin by denoting the first position --- the one immediately to the left of the first character --- interesting, and going from there.
Lemma (Second observation): If  is the longest palindrome centered at the current position, and
is the longest palindrome centered at the current position, and  is the longest palindromic proper suffix of , then all positions between the current position and the centre of may safely be denoted uninteresting.
is the longest palindromic proper suffix of , then all positions between the current position and the centre of may safely be denoted uninteresting.
Proof: Consider some position between the centres of and . Suppose there exists a palindromic substring, 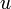 , of length greater than or equal to that of , centered at . Certainly the last character of lies to the right of the last character of , since is centered further to the right and is longer. So we repeatedly remove one character from each end of until and end at the same position. Since is now shorter than (since its centre is to the right but both and extend equally far on the right), it is a palindromic proper suffix of . Since the centre of is to the left of the centre of , is longer than , a contradiction as is maximal by hypothesis.
, of length greater than or equal to that of , centered at . Certainly the last character of lies to the right of the last character of , since is centered further to the right and is longer. So we repeatedly remove one character from each end of until and end at the same position. Since is now shorter than (since its centre is to the right but both and extend equally far on the right), it is a palindromic proper suffix of . Since the centre of is to the left of the centre of , is longer than , a contradiction as is maximal by hypothesis.
To find the longest palindromic proper suffix, we make yet another observation: the longest palindromic proper suffix and the longest palindromic proper prefix are reflections of each other about the current centre. So we scan backward from the current position. For each position to the left of the current position, we know the longest palindromic substring centered there. If the first character of is to the right of the first character of , then the longest palindromic substring centered at the position obtained by reflecting about the current position is identical to . (If it were possible to extend it, it would also be possible to extend .) This means we can fill in the corresponding position in the longest palindromic array immediately, and also that there is no palindromic prefix of centered at as , and hence no corresponding palindromic suffix at the position obtained by reflecting across the current centre. Otherwise, on the other hand, we know there is a palindromic (proper) prefix centered at , which means there is a palindromic (proper) suffix centered at the position obtained by reflecting across the current centre. Furthermore, since we are scanning backward from the current centre, the first such we encounter is the centre of the longest palindromic proper prefix, so we have also found the longest palindromic proper suffix.
These facts give us enough information to construct an algorithm:
- (Initialization) Fill in the first entry of the longest palindrome array; it is zero, for this corresponds to the position just before the beginning of the string. Start at the position right on the first character of the string. This is the first interesting position. Also, we need to keep track of the length of the currently longest known palindrome centered at the current position. This starts out as one (the character itself).
- (Test interesting position) Check whether the palindrome we have so far centered at the current position can be extended (that is, whether there exist identical characters immediately to the left and right of it). If so, extend it. Do this repeatedly until it cannot be extended anymore, either because it is a prefix/suffix of the entire string, or because the next characters on the left and right do not match.
- We now know the length of the longest palindrome centered at the current location. Fill this in.
- (Find next interesting position) Let scan backward through the longest palindrome array and
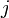 scan forward, so that and are reflections across the current position. Note that the entry for is always known beforehand.
scan forward, so that and are reflections across the current position. Note that the entry for is always known beforehand.
- If is after the last position in the string, we have computed all entries in the longest palindrome array, and the algorithm halts. (This always happens eventually.)
- Otherwise, if the longest palindrome centered at has its first character to the right of the first character of the longest palindrome centered at our current position, then its length
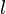 is also the length of the longest palindrome centered at . Fill this in.
is also the length of the longest palindrome centered at . Fill this in. - Otherwise, the longest palindrome centered at is at least as long as the longest palindrome centered at . is the next interesting position. Go back to step 2, setting the current position to and the length of the currently longest known palindrome centered there to .
- If
It should now be clear that this algorithm is correct, but it is not necessarily clear that it is efficient.
Theorem: Manacher's algorithm runs in linear time.
Proof:
- The outer loop runs times.
- Step 1 takes constant time and is executed once.
- Step 2 contains a loop. Each iteration of the loop takes constant time and examines two characters of the string, one on the left of the current palindrome and one on the right. Call the pointer to the next character on the right to examine
 . After each iteration of the inner loop, either it runs again immediately, moving one character to the right or step 3 and step 4 follow, which either terminate the algorithm or move the current position to the right, keeping fixed. (This is because we always move to a suffix in step 4.) So after each iteration either or the current position is advanced, and thus total number of iterations of the loop in step 2 is no more than the sum of
. After each iteration of the inner loop, either it runs again immediately, moving one character to the right or step 3 and step 4 follow, which either terminate the algorithm or move the current position to the right, keeping fixed. (This is because we always move to a suffix in step 4.) So after each iteration either or the current position is advanced, and thus total number of iterations of the loop in step 2 is no more than the sum of 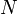 , the number of characters, and
, the number of characters, and 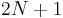 , the number of positions. So the total time spent in step 2 is .
, the number of positions. So the total time spent in step 2 is . - Step 3 takes constant time and is executed once per iteration of the outer loop.
- Step 4 consists of some constant-time parts executed once per iteration of the outer loop, as well as an inner loop. The inner loop takes constant time per iteration can only run times in total, because each iteration fills in a previously unknown entry in the longest palindrome array, which has entries.
Overall, each step contributes to the running time, and so Manacher's algorithm is overall.
References[edit]
- ↑ Juha Kärkkäinen and Peter Sanders. 2003. Simple linear work suffix array construction. In Proceedings of the 30th international conference on Automata, languages and programming (ICALP'03), Jos C. M. Baeten, Jan Karel Lenstra, Joachim Parrow, and Gerhard J. Woeginger (Eds.). Springer-Verlag, Berlin, Heidelberg, 943-955. Retrieved 2010-11-13 from http://monod.uwaterloo.ca/~cs482/suffix-icalp03.pdf.
- ↑ Toru Kasai, Gunho Lee, Hiroki Arimura, Setsuo Arikawa, and Kunsoo Park. 2001. Linear-Time Longest-Common-Prefix Computation in Suffix Arrays and Its Applications. In Proceedings of the 12th Annual Symposium on Combinatorial Pattern Matching (CPM '01), Amihood Amir and Gad M. Landau (Eds.). Springer-Verlag, London, UK, 181-192.
- ↑ E. Ukkonen. (1995). On-line construction of suffix trees. Algorithmica 14(3):249-260. PDF | PDF with figures
- ↑ Gabow, H. N.; Tarjan, R. E. (1983), "A linear-time algorithm for a special case of disjoint set union", Proceedings of the 15th ACM Symposium on Theory of Computing (STOC), pp. 246–251, doi:10.1145/800061.808753
- ↑ Fred Akalin. Finding the longest palindromic substring in linear time. Retrieved 2016-10-01 from https://www.akalin.com/longest-palindrome-linear-time. (This source contains a Python implementation of the simple linear-time algorithm.)
- ↑ Glenn Manacher. 1975. A New Linear-Time "On-Line" Algorithm for Finding the Smallest Initial Palindrome of a String. J. ACM 22, 3 (July 1975), 346-351. DOI=10.1145/321892.321896 http://doi.acm.org/10.1145/321892.321896
- ↑ Alberto Apostolico, Dany Breslauer, and Zvi Galil (1994), "Parallel Detection of all Palindromes in a String", Comput. Sci.
Code[edit]
C++ implementation of Manacher's algorithm
External links[edit]
- SPOJ problems:
- The problem Calf Flac from the USACO training pages can be solved using the naive algorithm. ilove youuuuuuuuuuuuu